You probably have a fairly decent understanding of how an Erlang project should be structured by now. Along with any guide about the language basics, you should be mostly good to get started. However, there are a few complex topics that are currently not covered well in any of the Erlang documentation out there. In this chapter, we’ll go through the task of providing guidance around handling Unicode, time, and SSL/TLS configurations.
Do note that those are three complex topics on their own. While we’re going to provide some background information on each of them, you are not going to be an expert at handling them right away—it just helps to know how much complexity exists to avoid huge mistakes.
Handling Unicode
Erlang’s got quite a bad reputation for string handling. A lot of this comes from not having a dedicated string type, and for years, not having decent unicode support outside of community libraries. While the former has not changed, there are some strengths to that approach, and the latter has finally been addressed in recent Erlang releases.
Background Information on Unicode
Unicode, in a nutshell, is a set of standards about how text should be handled in computers, regardless of the user’s language (real languages, not programming languages). It has become a huge specification with a lot of exceedingly complex considerations about all kinds of details, and developers are often reasonably getting lost in it.
Even without knowing all about Unicode, you can know enough to be effective and avoiding all of the most glaring mistakes. To get started, we’ll introduce a bit of terminology:
- character: the word “character” is defined kind of vaguely in Unicode. Every time you see the word “character”, imagine that the person talking to you is using a very abstract term that can mean anything from a letter in a given alphabet, some drawings (like emojis), accents or letter modifiers (like
¸andc, which becomesç), control sequences (like “backspace”), and so on. It’s mostly a common but inaccurate way to refer to bits of text, and you must not attach too much meaning to it. Unicode has better and exact definitions of its own. - code point: the Unicode standard defines all the possible basic fundamental “characters” you can have in a big list (and then some), each of which has a unique identifier. That identifier is the code point, often denoted
U+<hexadecimal number>. For example, “M” has the code pointU+004D, and ♻ has the code pointU+267B. You can see the Unicode Table for the full list. - encoding: While code points are just integers that represent an index by which you can look up, this is not sufficient to represent text in programming languages. Historically, a lot of systems and programming languages used bytes (
0..255) to represent all valid characters in a language. If you needed more characters, you had to switch languages. To be compatible with all kinds of systems, Unicode defines encodings, which allows people to represent sequences of code points under various schemes. UTF-8 is the most common one, using bytes for everything. Its representation shares the same basic structure as ASCII or Latin-1 did, and so it became extremely popular in Latin and Germanic languages. UTF-16 and UTF-32 are two alternatives that represent on wider sequences (16 or 32 bits). - code unit: A code unit specifies the way a given code point is encoded in a given encoding. Each code point takes from 1 to 4 code units for UTF-8. For example,
Ftakes only46as a code unit in UTF-8,0046in UTF-16, and00000046in UTF-32. By comparison,©has the code pointU+00A9, but is representable as two code units in UTF-8 (C2andA9), and one code unit in UTF-16 and UTF-32 (00A9and000000A9respectively). - glyph: the graphic representation of a character. For example,
U+2126is “Ohm sign”, represented asΩ, andU+03A9is “Greek Capital Letter Omega”, also represented by a similar-lookingΩ. In some Typefaces they will be the same, in some not. Similarly, the letter “a” is possibly representable by glyphs looking like “а” or “α”. Some code points have no associated glyphs (“backspace”, for example), and some glyphs can be used for ligatures representing multiple codepoints at once (such asæforae). - grapheme cluster: all of the terms mentioned so far have to do with very abstract concepts. Unicode has funky stuff like combining marks and ways to join multiple code points into one “character”. This can become super confusing because what a user considers a character and what a programmer considers a character are not the same thing. A grapheme cluster is a term meaning “a unit of text the user perceives as being a single character”. For example, the letter “ï” is composed of two code-points: the latin small letter
i(U+0069), and acombiningdiaeresis (¨asU+0308). So for a programmer, this will look like two code points, encoded with 3 code units in UTF-8. For a user though, they will expect that pressing “backspace” will remove both the diaeresis and the letter “i”.
That’s a lot of stuff, but those are important to know about. There is no direct relationship between how a programmer writes a character and how it ends up displayed to a user.
One particularly fun example is the ARABIC LIGATURE BISMILLAH AR-RAHMAN AR-RAHEEM, which is a single code point (U+FDFD), but represented graphically as “﷽”. This is currently the widest “character” in the Unicode standard. This represents an entire arabic sentence, and was added to the standard because it turns out to be a legal requirement in multiple Urdu documents, without their keyboard layouts having the ability to type arabic. It’s a great bit of unicode to mess with UI folks.
Most languages have problems with the fact that graphical (and logical) representations are not equal to the underlying codes creating the final character. Those exist for all kinds of possible ligatures and assemblies of “character parts” in various languages, but for Emojis, you can also make a family by combining individual people: 👩👩👦👦 is a family composed of 4 components with combining marks: 👩 + 👩 + 👦 + 👦, where + is a special combining mark (a zero width joiner) between two women and two boys (if you are viewing this document on an older browser, with an older font, or are checking out the PDF version of this book, then you might just see four people instead of a family.) If you were to go and consume that sequence byte by byte or codepoint by codepoint, you would break the family apart and change the semantic meaning of the text.
If you edit the text in a text editor that traditionally has good support for locales and all kinds of per-language rules, such as Microsoft Word (one of the few we know to do a great job of automatically handling half-width spaces and non-breakable spaces when languages ask for it), pressing backspace on 👩👩👦👦 will remove the whole family as one unit. If you do it in FireFox or Chrome, deleting that one ‘character’ will take you 7 backstrokes: one for each ‘person’ and one for each zero-width joining character. Slack will consider them to be a single character and visual studio code behaves like the browsers (even if both are electron apps), and notepad.exe or many terminal emulators will instead expand them as 4 people and implicitly drop the zero-width joining marks.
This means that no matter which programming language you are using, if strings look like arrays where you can grab “characters” by position or through some index, you are likely to have serious problems.
Worse than this, some “characters” have more than one acceptable encoding in Unicode. The character é can be created by encoding a single code point (U+00E9), or as the letter e (U+0065) followed by ´ (U+0301). This will logically be the same letter é in French, but two strings using the two different forms will not compare equal. Unicode therefore introduces concepts such as Normalization, which specifies how to coerce the representation of strings according to four possible standards: NFC, NFD, NFKC, and NFKD (if you don’t know which one to use, stick to NFC).
Sorting strings also introduces concepts such as Collations, which require knowing the current language being used when sorting.
In short, to support Unicode well in your programs, no matter in which programming language you work, you must treat strings as a kind of opaque data type that you manipulate exclusively through Unicode-aware libraries. Anything else and you are manipulating byte sequences or code point sequences and may end up breaking things unexpectedly at the human-readable level.
Handling Strings in Erlang
Erlang’s support for strings initially looks a bit funky: there is no dedicated string type. When considering all the complexity of Unicode though, it’s not actually all that bad. It’s usually as tricky to work with just one string type as it would be to work with no string types at all, because of all the possible alternative representations.
Folks using programming languages with variable string types that reflect multiple encodings may feel good about themselves right now, but you’ll see that Erlang has pretty decent Unicode support all things considered—only collations appear to be missing.
Data Types
In Erlang, you have to be aware of the following possible encodings for strings:
"abcdef": a string, which is directly made up of Unicode code points in a list. This means that if you write[16#1f914]in your Erlang shell, you’ll quite literally get"🤔"as a string, with no regards to encoding. This is a singly linked-list.<<"abcdef">>as a binary string, which is shorthand for<<$a, $b, $c, $d, $e, $f>>. This is an old standard list of Latin1 integers transformed as a binary. By default this literal format does not support Unicode encodings, and if you put a value that is too large in there (such as16#1f914) by declaring a binary like<<"🤔">>in your source file, you will instead find yourself with an overflow, and the final binary<<20>>. This is implemented with an Erlang binary (what is essentially an immutable byte array), and is meant to handle any kind of binary data content, even if it’s not text.<<"abcdef"/utf8>>as a binary Unicode string that is encoded as UTF-8. This one would work to support emojis. It is still implemented as an Erlang binary, but the/utf8constructor ensures proper Unicode encoding.<<"🤔"/utf8>>returns<<240,159,164,148>>, which is the proper sequence to represent the thinking emoji in UTF-8.<<"abcdef"/utf16>>as a binary string that is Unicode encoded as UTF-16.<<"🤔"/utf16>>returns<<216,62,221,20>><<"abcdef"/utf32>>as a binary string that is Unicode encoded as UTF-32.<<"🤔"/utf32>>returns<<0,1,249,20>>["abcdef", <<"abcdef"/utf8>>]: This is a special list dubbed “IoData” that can support multiple string formats. Your list can be codepoints as usual, but you’ll want all the binaries to all be the same encoding (ideally UTF-8) to prevent issues where encodings get mixed.
If you want to work with Unicode content, you will want to use the various string-related modules in Erlang.
The first one is string, which contains functions such as equal/2-4 to handle string comparison while dealing with case sensitivity and normalization, find/2-3 to look for substrings, length/1 to get the number of grapheme clusters, lexemes/2 to split a string on some pattern, next_codepoint/1 and next_grapheme/1 to consume bits of a string, replace/3-4 for substitutions, to_graphemes/1 to turn a string into lists of grapheme clusters, and finally functions like lowercase/1, uppercase/1, and titlecase/1 to play with casing. The module contains more content still, but that should be representative.
You will also want to use the unicode module to handle all kinds of conversions across string formats, encodings, and normalization forms. The regular expression module re handles unicode fine (just pass in the unicode atom to its options lists), and lets you use Generic Character Types if you pass in the ucp option. Finally, the file and io modules all support specific options to make unicode work fine.
All of these modules work on any form of string: binaries, lists of integers, or mixed representations. As long as you stick with these modules for string handling, you’ll be in a good position.
The one tricky thing you have to remember is that the encoding of a string is implicit. You have to know what it is when a string enters your system: an HTTP request often specifies it in headers, and so does XML. JSON and YAML mandate using UTF-8, for example. When dealing with SQL databases, each table may specify its own encoding, but so does the connection to the database itself! If any one of them disagrees, you’re going to corrupt data.
So you will want to know and identify your encoding very early on, and track it well. It’s not just a question of which data type in your language exists, it’s a question of how you design your entire system and handle exchanging data over the network.
There’s one more thing we can cover about strings: how to transform them effectively.
IoData
So which string type should you use? There are plenty of options, but picking one is not too simple.
The quick guidelines are:
- Binaries for UTF-8, which should represent the majority of your usage
- Binaries for UTF-16 and UTF-32, should you use them
- Lists as strings are rarely used in practice, but can be very effective if you want to work at the codepoint level
- Use IoData for everything else, particularly building strings.
One advantage of the binary data types is their ability to create subslices efficiently. So for example, I could have a binary blob with content such as <<"hello there, Erlang!">> and if I pattern match a subslice such as <<Txt:11/binary, _/binary>>, then Txt now refers to <<"hello there">> at the same memory location as the original one, but with no way to obtain the parent context programmatically. It’s a bounded reference to a subset of the original content. The same would not be true with lists, since they’re defined recursively.
On top of that, binaries larger than 64 bytes can be shared across process heaps, so you can cheaply move string content around the virtual machine without paying the same copying cost as you would with other data structure.
warning
Binary sharing is often a great way to gain performance in a program. However, there exist some pathological usage patterns where binary sharing can lead to memory leaks. If you want to know more, take a look at Erlang In Anger's chapter on memory leaks, particularly section 7.2
The real cool thing though comes from the IoData representation where you combine the list approach with binaries. It’s how you get really cheap composition of immutable strings:
Greetings = <<"Good Morning">>,
Name = "James",
[Greetings, ", ", Name, $!]
The final data structure here looks like [<<"Good Morning">>, ", ", "James", 33] which is a mixed list containing binary subsections, literal codepoints, strings, or other IoData structures. But the VM mechanisms all support handling it as if it were a flat binary string: The IO systems (both network and disk access), and the modules named in the previous section all seamlessly handle this string as Good Morning, James! with full Unicode support.
So while you can’t mutate strings, you can append and match a bunch of them in constant time, no matter the type they initially had. This has interesting implications if you’re writing libraries that do string handling. For example, if I want to replace all instances of & by &, and I started with <<"https://example.org/?abc=def&ghi=jkl"/utf8>>, I might instead just return the following linked list:
% a list
[%% a slice of the original unmutated URL
<<"https://example.org/?abc=def"/utf8>>,
%% a literal list with the replacement content
"&amp",
%% the remaining sub-slice
<<"ghi=jkl"/utf8>>
]
What you have then is a string that is in fact a linked list of 3 elements: a slice of the original string, the replaced subset, the rest of the original string. If you’re replacing on a document that’s taking 150MB in RAM and you have somewhat sparse replacements, you can build the entire thing and edit it with essentially no overhead. That’s pretty great.
So why else are IoData strings kind of cool? Well the unicode representation is one fun thing. As mentioned earlier, grapheme clusters are a crucial aspect of Unicode strings when you want to operate on them as a human would (rather than as binary sequences that only programmers would care about). Whereas most programming languages that use a flat array of bytes to represent strings have no great way to iterate over strings, Erlang’s string module lets you call string:to_graphemes(String) to play with them:
erl +pc latin1 # disable unicode interpretation
1> [Grapheme | Rest] = string:next_grapheme(<<"ß↑õ"/utf8>>),
[223 | <<226,134,145,111,204,131>>]
2> string:to_graphemes("ß↑õ"),
[223,8593,[111,771]]
3> string:to_graphemes(<<"ß↑õ"/utf8>>),
[223,8593,[111,771]]
This lets you take any unicode string, and turn it into a list that is safe to iterate using calls such as lists:map/2, lists comprehensions, or pattern matching. This can only be done through IoData, and this might even be a better format than what you’d get with just default UTF-8 binary strings.
Do note that pattern matching is still risky there. Ideally you’d want to do a round of normalization first, so that characters that can be encoded in more than one way are forced into a uniform representation.
This should hopefully demistify Erlang’s strings.
Handling Time
Time is something very simple to live, but absurdly difficult to describe. It has taken philosophers and scientists centuries of debate to kind of get to a general agreement, and we software folks decided that counting seconds since January 1st 1970 ought to be good enough. It’s harder than that. We won’t get into all the details about calendaring rules and conversions, timezones, concepts of leap seconds and so on; that’s too general a topic. However, we’ll cover some important distinctions between wall clocks and monotonic time, and how the Erlang virtual machine can help us deal with this stuff.
Background Information on Time
If we want to be very reductionist, there are a few specific use cases for time measurements, and they are often rather distinct:
- Knowing the duration between two given events, or “how long does something take?”, which requires having a single value in a unit such as microseconds, hours, or years
- Placing an event on the timeline in a way we can pinpoint it and understand when it happened, or “when does something happen?”, usually based on a datetime.
Essentially those both have to do with time, but are not measured the same way.
The short answer for Erlang is that you should use erlang:monotonic_time/0-1 to calculate durations, and erlang:system_time/0-1 for the system time (such as a UNIX timestamp). If you want to understand why, then you will want to read the rest of this chapter.
A datetime is usually based on a calendar date (most of readers are likely using the Gregorian Calendar) along with a given hour, minute, and seconds value, along with a timezone and optionally, a higher precision value for milliseconds or microseconds. This value needs to be understandable by humans, and is entirely rooted into a social system that people agree means something for a given period of time: we all know that the year 1000 refers to a specific part of time even if our current Gregorian calendar was introduced in 1582 and technically none of the dates before have happened under that system – they may have been lived under the Julian calendar or the mayan calendar, but not the gregorian one. The whole concept is eventually attached to astronomical phenomena such as Earth’s orbit, or mean solar days.
On the other hand, a time interval, particularly for computers, is based on some cyclical event which we count. Water clocks or hourglasses would have a given rate at which drops or grains of sands would fall, and when it was empty, a given period of time would have gone through. Modern computers use various mechanisms like clock signals, crystal oscillators, or if you’re very fancy, atomic clocks. By synchronizing these cyclical countable events up with concepts such as solar days, we can adjust the measured cycles to a broader point of reference, and join our two time accounting systems: durations and pinpointing in time can be reconciliated.
We as humans are used to considering these two concepts as two facets of the same “time” value, but when it comes to computers, they’re really not that good at doing both at the same time. It really helps a lot if we keep both concepts distinct: durations are not the same thing as absolute points in times, and should be handled differently.
To give an example, many programmers are aware of Unix Time (a duration in seconds since January 1st 1970), and many programmers are aware of UTC as a standard. However, few developers are aware that both are actually tricky to convert because UTC handles leap seconds, but unix timestamps do not, and it can cause all kinds of weird, funny issues. Using them interchangeably can introduce subtle bugs in software.
One particular challenge is that computer clocks are not particularly good at being accurate over long periods of time, a concept known as clock drift. One result of this is that while we might have a very decent resolution over short intervals (a few minutes or hours), over weeks, months, or years, clocks drift a lot. The frequency of the computer clock varies here and there, but overall doesn’t change too much. All the short-time calculations you’ll make will be fine, but they won’t be good enough to keep track of most longer spans of time. Instead, protocols such as NTP are required to re-synchronize computer clocks with far more accurate (and more expensive) ones, over the network.
This means that it is to be expected that the time on your computer might just jump around for fun. Even more so if the operator just plays with things like changing timezones or system time.
Handling Time in Erlang
The way your computer handles time is based on the previously mentioned clocks that simply increment by counting microseconds or milliseconds (depending on hardware and operating systems). To represent time in units that makes sense to us humans, a conversion is done from some epoch (an arbitrary starting point) to some time standard (UTC). Because computer clocks drift and shift with time, an offset value is kept that enables correcting the local ever-increasing clock so that it makes sense to people. This is usually all hidden, and unless you know where to look, you won’t know it happens.
Erlang’s runtime system uses the same kind of mechanisms, but makes them explicit. It exposes two clocks:
- A monotonic clock, which means a clock that is just a counter that always returns increasing values (or the same number as before, if you call it during the same microsecond). It can have a high precision and is useful to calculate intervals.
- A system clock, which exposes the time the user usually cares about as a human being. This tends to be done by using the unix POSIX time (seconds since January 1st 1970), which is widely used by computers everywhere, and plenty of conversion libraries exist for all other kinds of time formats. It presents a kind of lowest common denominator for human time.
Overall, all the clocks on your system may end up looking like Figure 1:
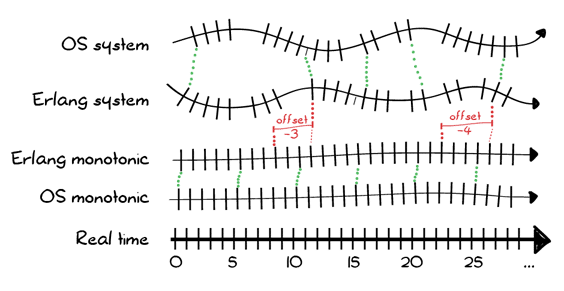
There is some real perceived time (which we’ll assume is rather constant, if we ignore relativistic effects), which the computer’s clock more or less matches. Voltage, temperature, humidity, and hardware quality may all impact its reliability. The Erlang VM provides its own monotonic clock, which is synchronized on the hardware clock (if any), and allows some additional control which we’ll describe soon.
The system time, for its own part, is always calculated as a given offset from its underlying monotonic clock. The objective is to take the arbitrary number of clock ticks of the hardware clock, and turn them into seconds from 1970, which can then be converted to other formats.
If the offset is a constant 0, then the VM’s monotonic and system times will be the same. If the offset is modified positively or negatively, the Erlang system time may be made to match the OS system time while the Erlang monotonic time is left independent. In practice, it is possible for the monotonic clock to be some large negative number, and the system clock to be modified by the offset to represent the positive POSIX timestamp.
This means that in Erlang, you’ll want to use the following functions for specific use cases:
erlang:monotonic_time/0-1for the Erlang monotonic time. It may return very low negative numbers, but they’ll never get more negative. You can use something likeT0=erlang:monotonic_time(millisecond), do_something(), T1=erlang:monotonic_time(millisecond)and get the total duration of the operation by calculatingT1 - T0. Note that the time units should be the same across comparisons (see notice).erlang:system_time/0-1for the Erlang system time (after the offset has been applied) when you need a UNIX timestamperlang:time_offset/0-1to figure out the difference between the Erlang monotonic and Erlang system clockscalendar:local_time/0to return the system time converted to the operating system’s current clock (meaning in the user’s current timezone and daylight saving times) in a{{Year, Month, Day}, {Hour, Minute, Second}}formatcalendar:universal_time/0to return the system time converted to the current time in UTC in a{{Year, Month, Day}, {Hour, Minute, Second}}format.
tip
The functions handling time in the erlang module almost all take a Unit argument, which can be one of second, millisecond, microsecond, nanosecond, or native. By default, the type of timestamp returned is in the native format. The unit is determined at run time, and erlang:convert_time_unit(Time, FromUnit, ToUnit) may be used to convert between time units. For example, erlang:convert_time_unit(1, seconds, native) returns 1000000000.
The calendar module also contains more utility functions, such as date validation, conversion to and from RFC3339 datetime strings (2018-02-01T16:17:58+01:00), time differences, and conversions to days, weeks, or detecting leap years.
The last tool in the arsenal is a new type of monitor, usable to detect when the time offset jumps. It can be called as erlang:monitor(time_offset, clock_service). It returns a reference and when time drifts, the message received will be {'CHANGE', MonitorRef, time_offset, clock_service, NewTimeOffset}.
Time Warping
If you use the previous functions in the right context, you’ll almost never have a problem handling time. The only thing you have to care about now is how to handle weird cases such as the host computer going to sleep and waking up with a brand new clock, dealing with a system administrator playing with the time, having NTP force a clock forwards and backwards in time, and so on. Not caring for them can make your system behave in very weird ways.
Fortunately, the Erlang VM lets you pick and choose from pre-established strategies, and as long as you stick with using the right functions at the right time (monotonic clocks for intervals and benchmarks, system time for pinpointing events in time), you can just choose whichever option you feel is more appropriate. Picking the right functions for the right use cases ensures that your code is time warp safe.
These options can be passed by passing the +C (warp mode) and +c (time correction) switches to the erl executable. The warp mode (+C) defines how the offset between monotonic and system time is handled, and the time correction (+c) defines how the VM will adjust the monotonic clock it exposes when the system clock changes.
+C multi_time_warp +c true: The time offset can change at any time without any limitations to provide good system time, and the Erlang monotonic clock frequency can be adjusted by the VM to be as accurate as possible. This is what you want to specify on any modern platform, and tends to have better performance, scale better, and behave better.+C no_time_warp +c true: The time offset is chosen at VM start time, and then is never modified. Instead, the monotonic clock is sped up or slowed down to slowly correct time drift. This is the default mode for backwards compatibility reasons, but you might want to pick a different one that is more in line with proper time usage.+C multi_time_warp +c false: The time offset can change at any time, but the Erlang monotonic clock frequency may not be reliable. If the OS system time leaps forwards, the monotonic clock will also leap forward. If the OS system time leaps backwards, the Erlang monotonic clock may pause briefly.+C no_time_warp +c false: The time offset is chosen at VM start time, and then is never modified. The monotonic clock is allowed to stall or jump forwards in large leaps. You generally do not want this mode.+C single_time_warp +c true: This is a special hybrid mode to be used on embedded hardware when you know Erlang boots before the OS clock is synchronized (for example, you boot your software before NTP synchronization can take place). When the VM boots, the Erlang monotonic clock is kept as stable as possible, but no system time adjustments are made. Once time synchronization is done at the OS level, the user callserlang:system_flag(time_offset, finalize), the Erlang system time warps once to match the OS system time, and then the clocks become equivalent to those underno_time_warp.+C single_time_warp +c false: This is a special hybrid mode to be used on embedded hardware when you know Erlang boots before the OS clock is synchronized (for example, you boot your software before NTP synchronization can take place). No attempts are made to synchronize the Erlang system time with the OS system time, and any changes in the OS system times may have impacts on the Erlang monotonic clock. Once time synchronization is done at the OS level, the user callserlang:system_flag(time_offset, finalize), the Erlang system time warps once to match the OS system time, and then the clocks become equivalent to those underno_time_warp
You generally want to always have +c true as an option (it’s the default), and to force +C multi_time_warp (which is not default). If you want to emulate old Erlang systems where clock frequency is adjusted, pick +C no_time_warp, and if you work in embedded systems where the first clock synchronization can jump really far in time and after that you expect it to be more stable and you don’t want +C multi_time_warp (you should want it!), then look for single_time_warp.
In short, if you can, pick +C multi_time_warp +c true. It’s the best option for accurate time handling out there.
SSL Configurations
Background Information on TLS
Coming Soon…
Handling TLS in Erlang
Coming Soon…