The biggest difference between Erlang and every other programming language out there is not in its concurrency, but rather in its fault tolerance. Almost everything in the language was designed for fault tolerance, and supervisors are one of the core parts of this design. In this chapter, we’ll cover the basics of supervision trees, what is in a supervisor, and how to structure supervision trees in your own system. When we’re done, you’ll be able to set up and manage most of the state your system will need.
Basics
Erlang is a kind of two-tiered language. At the lowest level, you have a functional subset. All you get is a bunch of data structures, functions, and pattern matching to modify and transform them. The data is immutable, local, and side-effects are rather limited if not unnecessary. At the higher level, you have the concurrent subset, where long-lived state is managed, and where it gets communicated from process to process.
The functional subset is rather straightforward and easy to learn with any of the resources mentioned in the book’s Introduction: you get a data structure, you change it, and return a new one. All program transformations are handled as pipelines of functions applied to a piece of data to get a new one. It’s a solid foundation on which to build.
The challenge of functional languages comes when you have to handle side-effects. How will you take something like a program’s configuration and pass it through the entire stack? Where is it going to be stored and modified? How do you take something inherently mutable and stateful, like a network stream, and embed it in an immutable and stateless application?
In most programming languages, this is all done in a rather informal and ad-hoc matter. In object-oriented languages, for example, we would tend to pick where side-effects live according to the boundaries of their domain, possibly while trying to respect principles such as persistence ignorance or hexagonal architecture.
In the end what you may end up with is a kind of layered system where you hopefully have a bunch of pure domain-specific entities in the core, a bunch of interaction mechanisms on the outer edge, and a few layers in-between whose role is to coordinate and wrap all activities between entities:
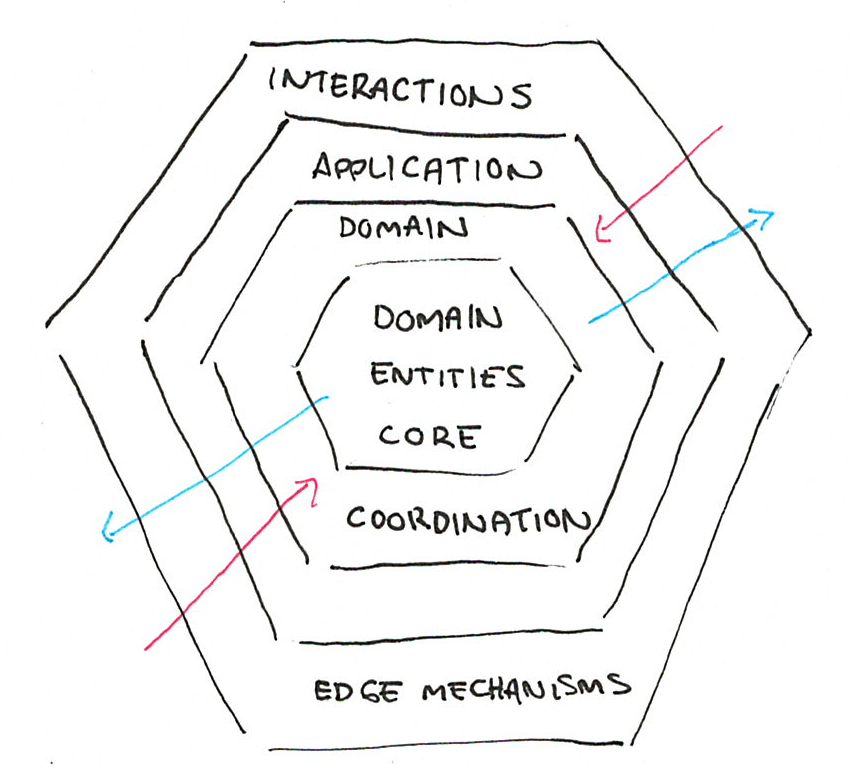
Figure 1: Hexagonal architecture as frequently recommended in OO design
The kind of structure this gives is usually very explicit regarding the domain modelling, but rather ambiguous with regards to how interactions and side-effects should be structured. How should failures contacting an external service bubble up? How would the inability to save a transformation on a core domain entity impact the outer-edge interactions when it comes from some event-driven mechanism?
The domain modelling you’d do in object-oriented systems can still be done in Erlang. We’d stick all of that in the functional subset of the language, usually in a library application that regroups all the relevant modules that do the changes and transformation you need, or in some cases within specific modules of a runnable application.
The richness of failure and fault handling, however, will be explicitly encoded within a supervision structure. Because the stateful parts of the system are encoded using processes, the structure of dependencies and their respective instantialization is all laid out for everyone to see:
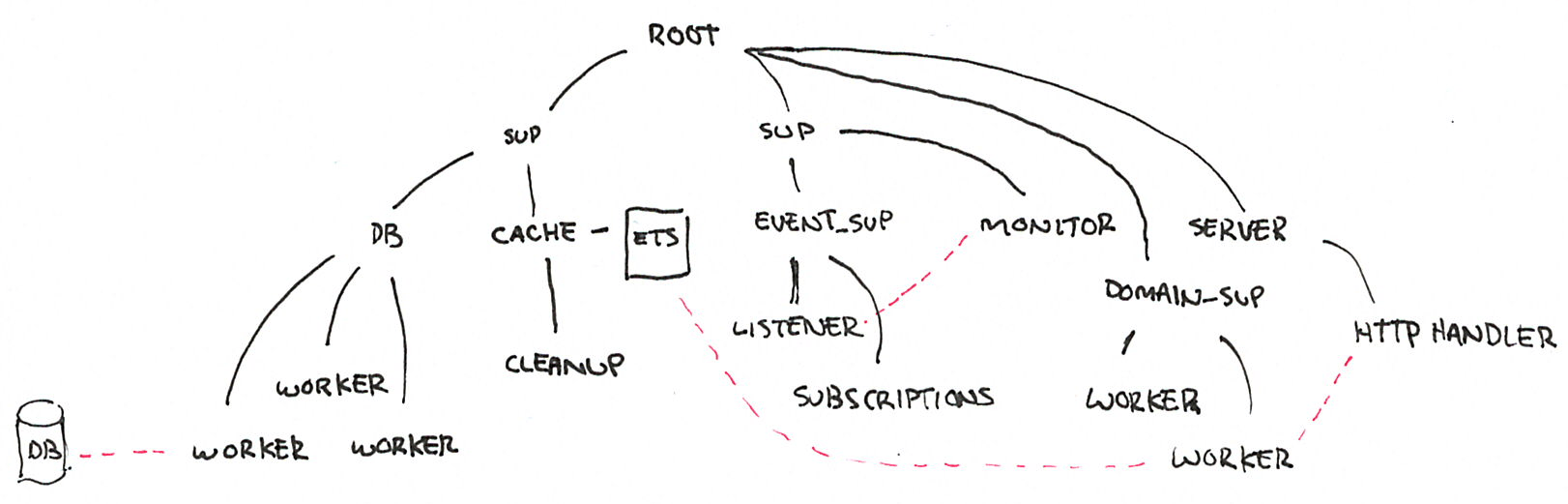
Figure 2: Sample supervision tree
In such a tree, all the processes are started depth-first, from left to right. This means that before the cache process and ETS table can be started, the database’s supervision structure (and all its workers), must first be started. Similarly, before the HTTP server and its handler can be started, the whole business domain subtree will have been to be created, and since it depends on the cache table, we will similarly ensure that this one (and the database workers) will be ready to go.
This supervision structure defines how the release starts, but it will also define how it shuts down: depth-first, from right to left. And even more than this, each supervisor can set its own policy and tolerance for child failures. This means that they also define which kind of partial failures are allowed or not in the system. Should the node still run if it can’t talk to the database? Maybe it should, but it can’t stay up if the cache becomes unavailable.
In a nutshell, where functional stuff can be used for the domain-specific handling, the flow of state, events, and interactions with the outside world is codified and explicit in stateful components, giving us a whole new way to handle errors and initialization.
We’ll see how to do this in a moment, but first, let’s review how supervisors work.
What’s in a Supervisor
Supervisors are one of the simplest behaviours in all of Erlang/OTP on the surface. They take a single init/1 callback, and that’s about it. The callback is used to define the children of each supervisor, and to configure some basic policies in how they react to failures of many kind.
There are 3 types of policies to handle:
- The supervisor type
- The restart policy of a child
- The frequency of failures to be accepted
Each of them is simple enough in isolation, but choosing good ones can become a bit tricky. Let’s start with the supervisor type:

Figure 3: The three supervisor types
There are three types of strategies:
one_for_one, which states that each child is independent from the other children. If one dies, the others don’t need any replacing or modification.simple_one_for_oneis a specialization ofone_for_onein the case where all the children are of the same type (say a worker pool), which is faster and lighter weight
rest_for_oneencodes a linear dependency between the supervisor’s children. If one of them dies, all those started after it must be restarted, but not those started before. In a scenario where processCdepends on processB, andBdepends on processA, therest_for_onestrategy allows efficient encoding of their dependency structure.one_for_allis a strategy by which if any child dies, then all of them must also be restarted. This is the type of supervisor you’d want to use when there is a strong interdependency between all children; if any one of them restarts, there’s no easy way for the other ones to recuperate, and so they should also be restarted.
These strategies are effectively all about how errors should propagate between children of the supervisor. The next bit to consider is how each of the processes that fail should, on their own, be handled by the supervisor after the signals have been propagated.
| Restart Policy | On Normal Exit | On Abnormal Exit |
|---|---|---|
| permanent | restart | restart |
| transient | stay dead | restart |
| temporary | stay dead | stay dead |
This lets you say that some processes are expected to never stop (permanent), some are expected to stop (transient), and some are expected to fail (temporary).
The final bit of configuration we can set is the frequency at which restarts are allowed. This is done through two parameters, intensity and period, which respectively stand for how many crashes have been spotted and during how many seconds they took place. We can then specify that a supervisor should tolerate only one crash per hour, or a dozen per second if we want it so.
This is how you declare a supervisor:
-module(myapp_sup).
-behaviour(supervisor).
%% API
-export([start_link/0]).
%% Supervisor callbacks
-export([init/1]).
-define(SERVER, ?MODULE).
start_link() ->
supervisor:start_link({local, ?SERVER}, ?MODULE, []).
init([]) ->
{ok, {{one_for_all, 1, 10}, [ % one failure per 10 seconds
#{id => internal_name, % mandatory
start => {mymod, function, [args]}. % mandatory
restart => permanent, % optional
shutdown => 5000, % optional
type => worker, % optional
modules => [mymod]} % optional
]}}.
You can define as many children as you want at once in there (except for simple_one_for_one, which expects a description template). Other arguments you can specify for a child include shutdown, which gives a number of milliseconds to wait for the proper termination of the child (or brutal_kill to kill it right away), and a definition on whether a process is a worker or a supervisor. This type field, along with modules, are only used when doing live code upgrades with releases, and the latter can generally be ignored and be left to its default value.
That’s all that’s needed. Let’s see how we can put that in practice.
Trying Your Own Supervisor
Let’s try to add a supervisor with a worker to an application, running what is essentially the heaviest Hello World on the planet. We’ll build a whole release for that:
$ rebar3 new release hello_world
===> Writing hello_world/apps/hello_world/src/hello_world_app.erl
===> Writing hello_world/apps/hello_world/src/hello_world_sup.erl
===> Writing hello_world/apps/hello_world/src/hello_world.app.src
===> Writing hello_world/rebar.config
===> Writing hello_world/config/sys.config
===> Writing hello_world/config/vm.args
===> Writing hello_world/.gitignore
===> Writing hello_world/LICENSE
===> Writing hello_world/README.md
$ cd hello_world
You should recognize the release structure, where all OTP applications are in the apps/ subdirectory.
Open up hello_world_sup module, and make sure it looks like this:
%%%----------------------------------------------------------
%% @doc hello_world top level supervisor.
%% @end
%%%----------------------------------------------------------
-module(hello_world_sup).
-behaviour(supervisor).
-export([start_link/0]).
-export([init/1]).
-define(SERVER, ?MODULE).
start_link() ->
supervisor:start_link({local, ?SERVER}, ?MODULE, []).
init([]) ->
SupFlags = #{strategy => one_for_all,
intensity => 0,
period => 1},
ChildSpecs = [
#{id => main,
start => {hello_world_serv, start_link, []}}
],
{ok, {SupFlags, ChildSpecs}}.
This establishes a single child, which will be in the module hello_world_serv. This will be a straightforward gen_server that does nothing, using only its init function:
-module(hello_world_serv).
-export([start_link/0, init/1]).
start_link() ->
gen_server:start_link(?MODULE, [], []).
init([]) ->
%% Here we ignore what OTP asks of us and just do
%% however we please.
io:format("Hello, heavy world!~n"),
halt(0). % shut down the VM without error
This file just starts an OTP process, outputs Hello, heavy world!, and then shuts the whole virtual machine down.
Let’s build a release and see what happens:
$ rebar3 release
===> Verifying dependencies...
===> Compiling hello_world
===> Starting relx build process ...
===> Resolving OTP Applications from directories:
/Users/ferd/code/self/adoptingerlang/hello_world/_build/default/lib
/Users/ferd/code/self/adoptingerlang/hello_world/apps
/Users/ferd/bin/erls/21.1.3/lib
===> Resolved hello_world-0.1.0
===> Dev mode enabled, release will be symlinked
===> release successfully created!
And now we can start it. We’ll use the foreground argument, which means we’ll boot the release to see all of its output, but do so in a non-interactive mode (without a shell):
$ ./_build/default/rel/hello_world/bin/hello_world foreground
<debug output provided by wrappers bundled with Rebar3>
Hello, heavy world!
What happens here is that the tools generate a script at /_build/default/rel/hello_world/bin/hello_world. This script puts a bunch of stuff together to make sure your release boots with all the right configuration and environment values.
Everything starts with the virtual machine starting, and eventually spawning the root process in Erlang itself. The kernel OTP application boots, and then sees in the config data that it has to start the hello_world application.
This is done by calling hello_world_app:start/2, which in turn calls hello_world_sup, which starts the hello_world_serv process, which outputs text and then makes a hard call to the VM telling it to shut down.
And that’s what we just did. Supervisors only start and restart processes; they’re simple, but their power comes from how they can be composed and used to structure a system.
Structuring Supervision Trees
The most complex part of supervisors isn’t their declaration, it’s their composition. They’re a simple tool up to a complex task. In this section, we’ll cover why supervision trees can work, and how to best structure them to gain the most out of them.
What Makes Supervisors Work
Everyone has heard “have you tried turning it off and on again?” as a general bug-fixing approach. It works surprisingly often, and Erlang supervision trees operate under that principle. Of course, restarting can’t solve all bugs, but it can cover a lot.
The reason restarting works is due to the nature of bugs encountered in production systems. To discuss this, we have to refer to the terms Bohrbug and Heisenbug coined by Jim Gray in 1985. Basically, a bohrbug is a bug that is solid, observable, and easily repeatable. They tend to be fairly simple to reason about. Heisenbugs by contrast, have unreliable behaviour that manifests itself under certain conditions, and which may possibly be hidden by the simple act of trying to observe them. For example, concurrency bugs are notorious for disappearing when using a debugger that may force every operation in the system to be serialised.
Heisenbugs are these nasty bugs that happen once in a thousand, million, billion, or trillion times. You know someone’s been working on figuring one out for a while once you see them print out pages of code and go to town on them with a bunch of markers.
With these terms defined, let’s look at how easy it should be to find bugs in production:
| Type of Feature | Repeatable | Transient |
|---|---|---|
| Core | Easy | Hard |
| Secondary | Easy (often overlooked) | Hard |
If you have bohrbugs in your system’s core features, they should usually be very easy to find before reaching production. By virtue of being repeatable, and often on a critical path, you should encounter them sooner or later, and fix them before shipping.
Those that happen in secondary, less used features, are far more of a hit and miss affair. Everyone admits that fixing all bugs in a piece of software is an uphill battle with diminishing returns; weeding out all the little imperfections takes proportionally more time as you go on. Usually, these secondary features will tend to gather less attention because either fewer customers will use them, or their impact on their satisfaction will be less important. Or maybe they’re just scheduled later and slipping timelines end up deprioritising their work.
Heisenbugs are pretty much impossible to find in development. Fancy techniques like formal proofs, model checking, exhaustive testing or property-based testing may increase the likelihood of uncovering some or all of them (depending on the means used), but frankly, few of us use any of these unless the task at hand is extremely critical. A once in a billion issue requires quite a lot of tests and validation to uncover, and chances are that if you’ve seen it, you won’t be able to generate it again just by luck.
So let’s take a look at the previous table of bug types, but let’s focus on how often they will happen in production:
| Type of Feature | Repeatable | Transient |
|---|---|---|
| Core | Should Never | All the time |
| Secondary | Pretty often | All the time |
First of all, easy repeatable bugs in core features should just not make it to production. If they do, you have essentially shipped a broken product and no amount of restarting or support will help your users. Those require modifying the code, and may be the result of some deeply entrenched issues within the organisation that produced them.
Repeatable bugs in side-features will pretty often make it to production. This is often a result of not taking or having the time to test them properly, but there’s also a strong possibility that secondary features often get left behind when it comes to partial refactorings, or that the people behind their design do not fully consider whether the feature will coherently fit with the rest of the system.
On the other hand, transient bugs will show up all the damn time. Jim Gray, who coined these terms, reported that on 132 bugs noted at a given set of customer sites, only one was a Bohrbug. 131/132 of errors encountered in production tended to be heisenbugs. They’re hard to catch, and if they’re truly statistical bugs that may show once in a million times, it just takes some load on your system to trigger them all the time; a once in a billion bug will show up every 3 hours in a system doing 100,000 requests a second, and a once in a million bug could similarly show up once every 10 seconds on such a system, but their occurrence would still be rare in tests.
That’s a lot of bugs, and a lot of failures if they are not handled properly. Let’s rework the table, but now we’re considering whether restarts can handle these faults:
| Type of Feature | Repeatable | Transient |
|---|---|---|
| Core | No | Yes |
| Secondary | It depends | Yes |
For repeatable bugs on core features, restarting is useless. For repeatable bugs in less frequently used code paths, it depends; if the feature is a thing very important to a very small amount of users, restarting won’t do much. If it’s a side-feature used by everyone, but to a degree they don’t care much about, then restarting or ignoring the failure altogether can work well.
For transient bugs though, restarting is extremely effective, and they tend to be the majority of bugs you’ll meet live. Because they are hard to reproduce, that their showing up is often dependent on very specific circumstances or interleavings of bits of state in the system, and that their appearance tends to be in a very small fraction of all operations, restarting tends to make them disappear altogether.
Supervisors allows a part of your system hit by such a bug to roll back to a known stable state. Once you’ve rolled back to that state, trying again is unlikely to hit the same weird context that caused the first bug. And just like that, what could have been a catastrophe has become little more than a hiccup for the system, something users quickly learn to live with.
It’s About the Guarantees
One very important part of Erlang supervisors and their supervision trees is that their start phase is synchronous. Each OTP Process started has a period during which it can do its own thing, preventing the entire boot sequence of its siblings and cousins to come. If the process dies there, it’s retried again, and again, until it works, or fails too often.
That’s where people make a very common mistake. There isn’t a backoff or cooldown period before a supervisor restarts a crashed child. When people write a network-based application and try to set up a connection in this initialization phase, and that the remote service is down, the application fails to boot after too many fruitless restarts. Then the system may shut down.
Many Erlang developers end up arguing in favor of a supervisor that has a cooldown period. This sentiment is wrong for one simple reason: it’s all about the guarantees.
Restarting a process is about bringing it back to a stable, known state. From there, things can be retried. When the initialization isn’t stable, supervision is worth very little. An initialized process should be stable no matter what happens. That way, when its siblings and cousins get started later on, they can be booted fully knowing that the rest of the system that came up before them is healthy.
If you don’t provide that stable state, or if you were to start the entire system asynchronously, you get very little benefit from this structure that a try ... catch in a loop wouldn’t provide.
Supervised processes provide guarantees in their initialization phase, not a best effort. This means that when you’re writing a client for a database or service, you shouldn’t need a connection to be established as part of the initialization phase unless you’re ready to say it will always be available no matter what happens.
You could force a connection during initialization if you know the database is on the same host and should be booted before your Erlang system, for example. Then a restart should work. In case of something incomprehensible and unexpected that breaks these guarantees, the node will end up crashing, which is desirable: a pre-condition to starting your system hasn’t been met. It’s a system-wide assertion that failed.
If, on the other hand, your database is on a remote host, you should expect the connection to fail. In this case, the only guarantee you can make in the client process is that your client will be able to handle requests, but not that it will communicate to the database. It could return {error, not_connected} on all calls during a net split, for example.
The reconnection to the database can then be done using whatever cooldown or backoff strategy you believe is optimal, without impacting the stability of the system. It can be attempted in the initialization phase as an optimization, but the process should be able to reconnect later on if anything ever disconnects.
If you expect failure to happen on an external service, do not make its presence a guarantee of your system. We’re dealing with the real world here, and failure of external dependencies is always an option.
Of course, the libraries and processes that call the client will then error out if they didn’t expect to work without a database. That’s an entirely different issue in a different problem space, but not one that is always impossible to work around. For example, let’s pretend the client is to a statistics service for Ops people—then the code that calls that client could very well ignore the errors without adverse effects to the system as a whole. In other cases, an event queue could be added in front of the client to avoid losing state when things go sour.
The difference in both initialization and supervision approaches is that the client’s callers make the decision about how much failure they can tolerate, not the client itself. That’s a very important distinction when it comes to designing fault-tolerant systems. Yes, supervisors are about restarts, but they should be about restarts to a stable known state.
Growing Trees
When you structure Erlang programs, everything you feel is fragile and should be allowed to fail has to move deeper into the hierarchy, and what is stable and critical needs to be reliable is higher up. Supervision structures allow the encoding of partial failures and fault propagation, so we must think properly about all of these things. Let’s take a look at our sample supervision tree again:
If a worker in the DB subtree dies, and DB is a supervisor with a one_for_one strategy, then we are encoding that each worker is allowed to fail independently from each other. On the other hand, if event_sup has a rest_for_one strategy, we are encoding in our system that the worker handling subscriptions must restart if the event listener dies; we say that there is a direct dependency.
Implicitly, there is also a statement that the event handling subtree is not directly impacted by the database, as long as it has managed to successfully boot at some point.
This supervision tree can be read like a schedule and a map to the system faults. The HTTP server won’t start unless the domain-specific workers are available, and the HTTP handler failing will not do anything that might compromise the database cache. Of course, if the HTTP handler relies on the domain worker, which relies on the cache’s ETS table and that table vanishes, then all these processes may die together.
What’s truly interesting here is that we can at a glance know how even unknown failures may impact our system. I don’t need to know why a database worker may fail, whether it’s due to a disconnection, a dying database, or a bug in the protocol implementation; I know that no matter what, this should leave the cache in place, and possibly let me do stale reads until the database sub-tree becomes available again.
This is where a child’s restart policy, combined with the supervisor’s accepted failure frequency comes in play. If all the workers and their supervisor are marked permanent, then there is a possibility that frequent crashes will take down the whole node. However, you can do a special little trick:
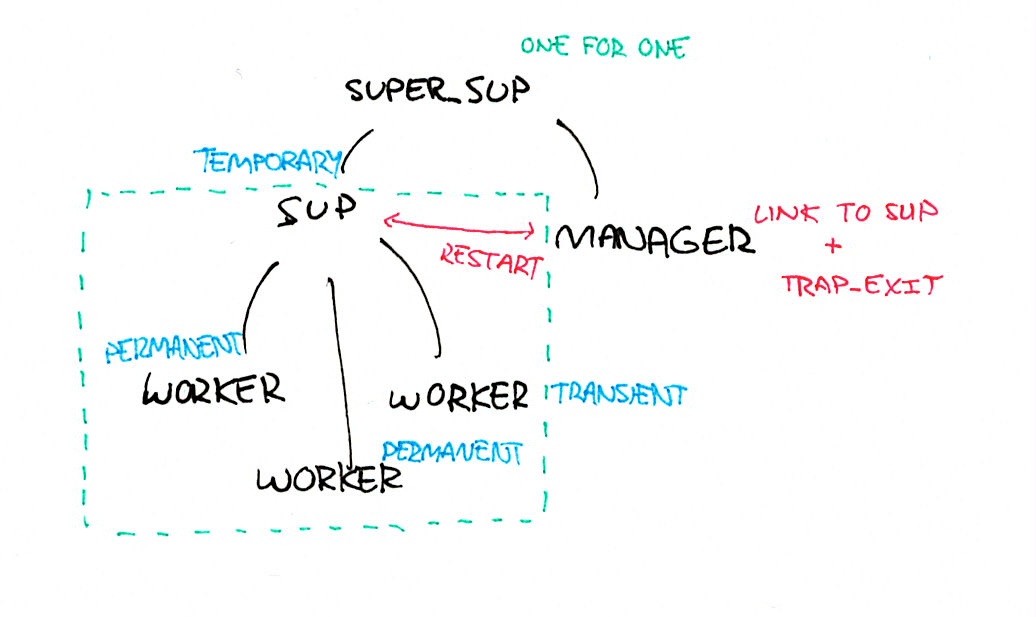
Figure 4: The manager worker pattern
- mark the workers as
permanentortransient, so that if they fail they get restarted - mark the workers’ direct supervisor (in the square) as
temporary, so that if it fails, it gives up and does not get restarted - add a new supervisor above it (this one can use any policy you want), but make it
one_for_one. - add a new process under the new supervisor (a sibling of the
temporarysupervisor). Have this process linked to the old supervisor. This is the manager.
The temporary supervisor can be used to tolerate an acceptable restart frequency. It could say that it’s normal for a worker to die every two minutes, for example. However, if we exceed this threshold, something bad is happening, and we want to stop retrying without risking to destabilize the node. The supervisor shuts down, and since it’s temporary, the super-supervisor (above the square) will just stay there doing nothing.
The manager can then look at whether the sup supervisor is alive or dead, and apply any policy it want when it comes to restarting it: use an exponential backoff, wait until a circuit breaker untrips, wait for an external service registry to say the dependent service is healthy again, or ask for user input on what to do. The manager can then ask its own parent supervisor to restart the temporary supervisor, which will then restart its own workers.
This is one of the few design patterns in Erlang. Because smart systems make stupid mistakes, we want to keep the supervisors as simple and predictable as they can be. The manager is us grafting a brain onto the supervisor, and making fancier decisions. This lets us separate policies for transient errors from policies for more major or persistent faults that can’t just be dealt with through restarting.
note
This pattern can be adapted however you want. The authors have, for example, used these two other variants for restart management:
- Multiple supervision trees are nested into each other, each representing a worker pool for a physical device. Each physical device is allowed to fail, go offline, or lose power. The managing process would routinely compare the running subtrees to a configuration service that was off-site. It would then start all the subtrees that were missing, and shut down all those that no longer existed. This let the manager handle run-time configuration synchronisation while also handling restarts for tricky hardware failure scenarios.
- The manager does nothing. However, the Erlang release shipped with a script that could be called by an operator. The script sent a message to the manager, asking it to restart the missing subtree. This variant was used because the subtree died only in the rarest of occasions (a whole region's storage going down) without wanting to kill the rest of the system, but upon recovery, operators could re-enable traffic that way.
While it would be difficult to bake that kind of functionality in a generic supervisor, a manager can easily provide the flexibility required for tailor-made solutions of this kind.
One exercise we would recommend you do is to take your system, and then draw its supervision tree on a white board. Go through all the workers and supervisors, and ask the following questions:
- Is it okay if this dies?
- Should other processes be taken down with this one?
- Does this process depend on anything else that will be weird once it restarts?
- How many crashes are too many for this supervisor?
- If this part of the system is flat out broken, should the rest of it keep working or should we give up?
Discuss these with your team. Shuffle supervisors around, adjust the strategies and policies. Add or remove supervision layers, and in some cases, add managers.
Repeat this exercise from time to time, and eventually do some chaos engineering by killing Erlang processes on a running node to see if it behaves and recovers the way you think it should (you can of course do chaos engineering on entire nodes, as is more common). What you’ll end up with is a fault tolerant piece of code. You will also build a team with a strong understanding of the failure semantics that are baked in their system, with a good mental model of how things should break down when they inevitably do. This is worth its weight in gold.